train_image_url and voice_name. The image file must be reachable at a publicly accessible URL (for example a presigned S3 GET URL), same as for video uploads.
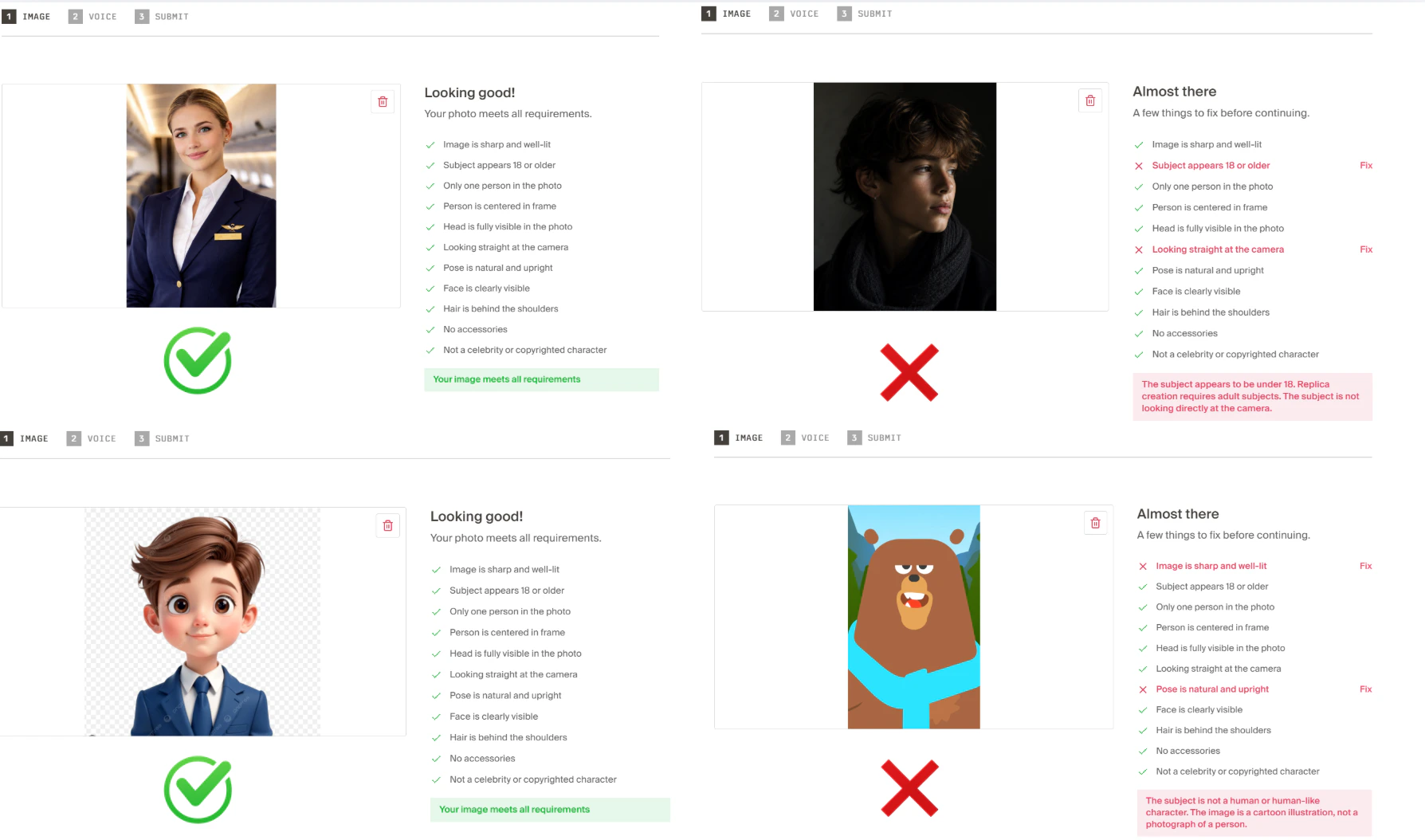
Image Requirements
Upload a clear, front-facing headshot that meets the following requirements:- Formats: JPG or PNG
- Minimum resolution: 512×512 pixels
- Only one person visible in the image
- Head and shoulders clearly visible in frame
- No glasses, hats, or face-covering accessories
- Avoid visible jewelry such as large earrings or necklaces
- Keep hair behind the shoulders and away from the face and neck
- Use even lighting with minimal shadows across the face
AI Image Fixer
If your uploaded image doesn’t fully meet the requirements above, setauto_fix_training_image to true when calling Create Replica. Tavus’s AI Image Fixer instantly fixes the uploaded image to fit our requirements, eliminating the need for editing or recapturing photos.
How voice_name works
Image-based training does not create a new voice from your source material. Instead, you must set voice_name to a stock voice identifier slug (for example anna). This selects a voice tied to an existing Tavus stock replica so the trained replica has a usable default voice.
Example voice_name values
Below are example voice_name slugs with a short sample clip for each.
When you run Conversational Video Interface (CVI) sessions later, you are not locked into that stock voice for every conversation. You can attach a persona whose TTS layer uses an external voice (from Cartesia or ElevenLabs). See Text-to-Speech (TTS) for how to set
external_voice_id and related fields.Consent, rights, and acceptable use
By using the image training API, you affirm that you have the rights to use the image you supply (for example likeness and publicity rights where applicable). Tavus may reject images that appear to depict unauthorized or impermissible subjects.Replica training typically takes 3–4 hours.